No products in the cart.
Uncategorized
Neural network scene understanding on Joker
30
Jan
Jan
Hello All,
Today I want to show you how Joker with SegNet project can be used for scene understanding (in AI world it’s called “semantic segmentation”). We will take picture of our room and AI will show us pixels belongs for different objects (like “table”, “chair”, etc). This tutorial should work on any Linux distribution (CoreOS, Debian, RedHat, etc). No GPU required, only CPU. I have brewed ready to use docker image, just issue following command in console:
docker run --name segnet --rm -it -v `pwd`/out:/workspace/out aospan/docker-segnet
you should see following output if input images processed successfully:
Grabbed camera frame in 12.1850967407 ms
Resized image in 33.4980487823 ms
Executed SegNet in 11251.4910698 ms
Processed results in 2.71892547607 ms
Input and processed images located in folder ./out. Let’s take a look at this images:


Left image is input and right is output annotated image. AI defined what object this pixel related for and mark with different colors.
Now you can prepare your own images and make experiments with AI semantic segmentation. Input images should be named strictly as example images (should be “img_003.png” not “img_3.png”) and located in folder ./in. In this case docker container should be started with following command:
docker run --name segnet --rm -it -v `pwd`/in:/workspace/in -v `pwd`/out:/workspace/out aospan/docker-segnet
Semantic segmentation performance
It’s take 11 seconds on Joker to process one image. This is too long for real time use-cases but ok for delayed processing. And there is some room for optimization too. Stay tuned !
Use case
Please check Joker Walker module for use-case of semantic segmentation.
Links and credits
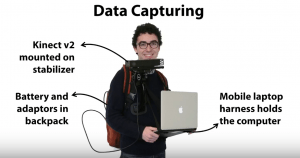
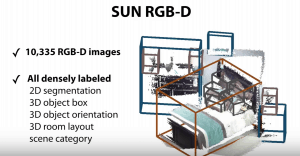
Here is some photos how this SUN RGB-D dataset was obtained (thanks for Princeton University Vision & Robotics Labs)
- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. University of Cambridge, UK.
- SegNet github repository
- SUN RGB-D dataset
- Github repo for docker image